What will the security stack for generative AI applications look like?
Generative AI will have broad-reaching impacts on security, affecting both offensive and defensive measures. Beyond the impact on existing attack vectors, there is an obvious new attack vector: the AI applications themselves. In this post, we’ll explore the security surface area of applications built with large language models (LLMs), and what tooling teams will need to secure their AI applications.
To state the obvious, not all AI is generative AI, and not all models are LLMs. Organizations have been developing AI models and using them in applications for years, but security for AI and ML is still a relatively new field, with a few up-and-coming vendors like Robust Intelligence, Calypso AI, HiddenLayer, and ProtectAI. The emergence of LLMs like OpenAI’s GPT-4, Meta’s LLaMa, and Anthropic’s Claude has introduced new ways for organizations to adopt AI, and are shifting the landscape of security concerns around AI models and applications. In this post, we’ll examine the security concerns of LLM-based applications based on two adoption models:
Apps leveraging a third-party LLM via API
Apps built on self-hosted, open-source LLMs
Apps leveraging a third-party LLM via API
Most of the generative AI applications that have popped up over the last year are built on top of APIs from OpenAI. In this scenario, the company developing and maintaining the LLM bears much of the responsibility for model security and robustness, but the application developer isn’t off the hook.
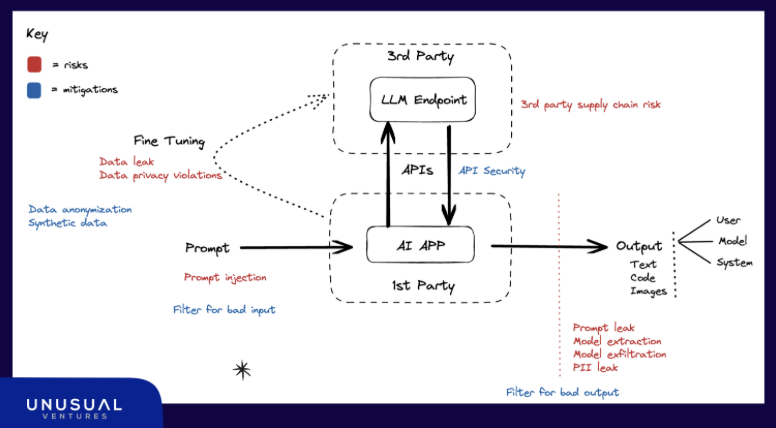
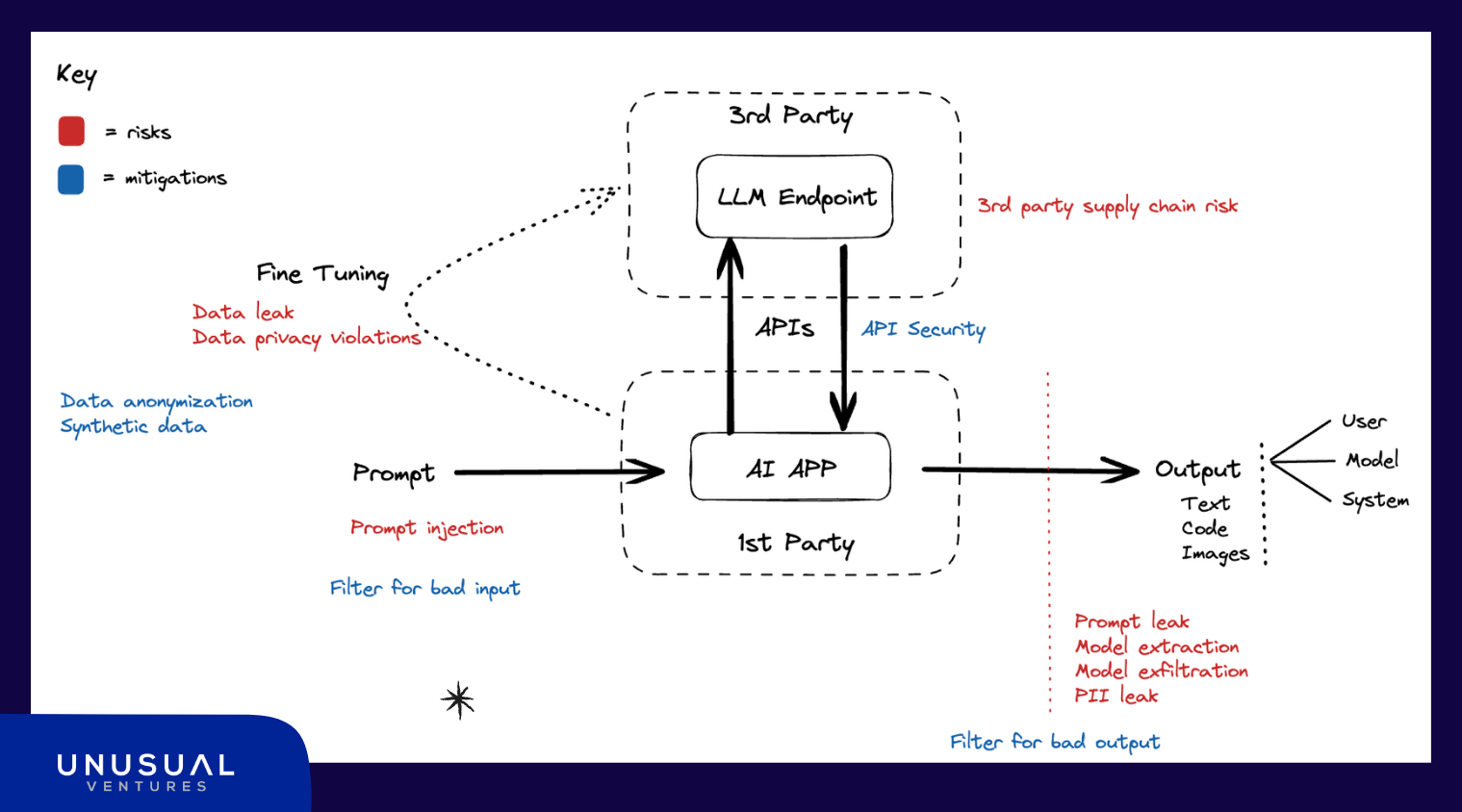
The simplified architecture for an API-based generative AI app (see diagram below), highlights several areas of risk:
Supply chain: In this scenario, there is third-party supply chain risk if the LLM provider is compromised. This is the same software supply chain risk that organizations face with any SaaS they’re using, but with potentially more consequential downstream effects. In some scenarios, the 3rd party could be running on an open-source LLM, many of which have not been vetted for security risks, and may be more easily exploitable due to their open nature. Organizations should consider these risks as they would any third-party risk, and take the vendor’s security posture into account when selecting a provider.
APIs: Data should be secured in transit over APIs between the first-party app and the third-party LLM, and API endpoints should be monitored and secured. Both the security of data in transit and API security can be addressed by existing security tools and practices.
Prompts: Prompt injection attacks are possible that seek to manipulate the model or force it to reveal its instruction prompt. If user prompts are used for fine-tuning, there may also be a risk of data poisoning from bad prompts.
OpenAI’s safety best practices recommend that developers constrain user inputs to minimize risk of prompt injection, and suggest that developers pass along user or session IDs to OpenAI so the company can monitor for abuse. Application developers might want the ability to audit and filter user-created prompts for their own monitoring purposes, and to prevent sharing sensitive information back to the third-party LLM developer.
Model output: Here it’s important to distinguish between security concerns and other “bad” model behavior. Most application developers don’t want their models spewing toxic content, but that’s a product issue, not a security issue. The big security concern is a data leak — whether the model accidentally regurgitates some PII, or reveals other training or prompt data. Organizations will want mechanisms to test model output, and filters to catch undesired model output in production.
Fine-tuning data: OpenAI provides mechanisms for customers to customize some models via fine-tuning. Currently, very few organizations building on top of LLM APIs are using fine-tuned models, but it’s worth discussing because of the data security concerns it adds. Much of the security risk in generative AI stems from training data, and the possibility that a model might memorize and regurgitate that data. For both security and privacy reasons, users might seek to anonymize their fine-tuning dataset or utilize synthetic data for fine-tuning (we’ve covered the various data preparation options in more detail here).
Apps built on self-hosted open-source LLMs
While today most generative AI app developers are leveraging APIs, we believe that in the future many organizations will shift toward hosting their own LLMs. The availability of open-source LLMs that are smaller but still highly performant will drive this shift. Organizations will leverage open-source models and fine-tuning to develop their own custom models. As AI app developers take on responsibility for the underlying model, they must address a new set of concerns in the model development process and in continuous maintenance of the model.
This diagram shows a simplified view of this model development process, and highlights key areas of risk:
OSS supply chain risk: Here the supply chain risk is of a different nature than the third-party risk described above. App developers will not build and train their own LLMs from scratch. Instead they will download pre-trained LLMs from open-source model libraries. OSS supply chain attacks where bad actors have attacked open-source code or planted malicious packages that look like legitimate packages have increased in recent years and we can expect the same risks to impact open source libraries for LLMs. Model scanning and other emerging evaluation tools can help organizations determine if a model is safe to use.
Fine-tuning data: As organizations move away from APIs toward developing their own custom LLMs from pre-trained models, we expect fine-tuning to play a bigger role. While self-hosting removes the risk of sharing data with a third-party, concerns about models memorizing and regurgitating training data remain the same. Strategies for anonymizing data sets or using entirely synthetic data should be considered depending on the nature of the data.
MLOps supply chain risk: Unlike API users, generative AI app developers fine-tuning their own self-hosted LLM must have their own framework for fine tuning. This will include closed-source and open-source MLOps tools, each of which introduce complexity and supply chain risk. Startups like ProtectAI, which provides a Jupyter notebook scanner, are working to address supply chain risks in the ML development process.
Model vulnerabilities: In the API scenario, OpenAI, Anthropic, or the hosted provider maintains the model and bears the majority of the responsibility for ensuring the model is robust and resistant to known vulnerabilities. In the self-hosted scenario, the application product owners are responsible for the model, and thus need a framework in place for testing and refining the model based on performance across various criteria including security. Robust Intelligence provides tools for model stress testing for security.
Though not illustrated here, AI app developers using their own self-hosted LLMs face the same security challenges around prompts and model output as AI app developers using APIs. Because they own the underlying model, AI app developers hosting their own LLMs have greater responsibility for protecting and maintaining the model. This might include increased protection and filtering on prompts (something like an AI firewall, also offered by Robust Intelligence), as well as continuous monitoring and testing for any degradation in performance on security measures.
The Gen AI security stack
We’ve discussed the risks for developers leveraging third-party LLMs via API or hosting their own LLMs built on pre-trained open-source models. So what do we think the generative AI security stack will look like long term? We believe that over time, most application developers will move away from using APIs and move towards hosting their own fine-tuned models. With that trend in mind, the following opportunities stand out:
Data preparation: products to help with preparation of data sets for fine-tuning, whether the organization pursues synthetic data (Gretel AI, Mostly AI, Tonic AI) or anonymization (Private AI)
Supply chain security: tools to validate the safety of open-source models and other software and components (Python packages, etc.) used in the ML supply chain (HiddenLayer, Socket, ProtectAI)
Testing and refining: a framework for testing and refining models before they go into production (Robust Intelligence, Calypso AI). Security is one key measure here, but may be rolled into a broader testing and refining framework that can also assess product quality (performance against desired behavior) and other AI safety measures such as privacy, bias, and toxicity.
Observability and detection: a way to monitor model performance in production and detect anomalous behavior that may indicate suspicious activity as well as degradations in performance that leave the model vulnerable (Robust Intelligence, Calypso AI). This should also include detection of prompt injection attacks or data poisoning attacks via malicious prompts.
To add a final disclaimer, these capabilities don’t constitute the entire security stack, and strong hygiene around identity and access management, data security, and cloud security are foundational. Many attacks on AI companies will come from familiar vectors faced by all software companies, as long as low hanging fruit continues to exist.
We’re excited to see how the security landscape around LLMs continues to evolve. If you’re building in the space, please don’t hesitate to reach out at allison@unusual.vc.